
用于低延迟日志记录的异步日志记录器
异步日志记录可以通过在单独的线程中执行 I/O 操作来提高应用程序的性能。Log4j 2 在此领域进行了多项改进。
- 异步日志记录器是 Log4j 2 中的新增功能。它们的目的是尽快从对 Logger.log 的调用返回到应用程序。您可以选择使所有日志记录器异步,或者使用同步和异步日志记录器的混合。使所有日志记录器异步将提供最佳性能,而混合则为您提供更大的灵活性。
- LMAX Disruptor 技术。异步日志记录器在内部使用 Disruptor(一个无锁线程间通信库)而不是队列,从而实现更高的吞吐量和更低的延迟。
- 作为异步日志记录器工作的一部分,异步追加器已得到增强,以便在批处理结束时(队列为空时)刷新到磁盘。这会产生与配置“immediateFlush=true”相同的结果,即所有接收到的日志事件始终在磁盘上可用,但效率更高,因为它不需要在每个日志事件上都访问磁盘。(异步追加器在内部使用 ArrayBlockingQueue,并且不需要在类路径上使用 disruptor jar。)
权衡
虽然异步日志记录可以带来显著的性能优势,但在某些情况下,您可能希望选择同步日志记录。本节介绍了异步日志记录的一些权衡。
优点
-
更高的峰值 吞吐量。使用异步日志记录器,您的应用程序可以以同步日志记录器的 6 到 68 倍的速度记录消息。
这对偶尔需要记录大量消息的应用程序特别有用。异步日志记录可以通过缩短等待下一个消息可以记录的时间来帮助防止或抑制延迟峰值。如果队列大小配置得足够大以处理突发,异步日志记录将有助于防止您的应用程序在活动突然增加时落后(太多)。
- 更低的日志记录响应时间 延迟。响应时间延迟是指在给定工作负载下,对 Logger.log 的调用返回所需的时间。异步日志记录器始终比同步日志记录器甚至基于队列的异步追加器具有更低的延迟。
- 错误处理。如果在日志记录过程中出现问题并抛出异常,异步日志记录器或追加器很难向应用程序发出此问题的信号。这可以通过配置
ExceptionHandler来部分缓解,但这可能仍然无法涵盖所有情况。因此,如果日志记录是您业务逻辑的一部分,例如,如果您使用 Log4j 作为审计日志记录框架,我们建议同步记录这些审计消息。(请注意,您仍然可以 组合它们,并使用异步日志记录进行调试/跟踪日志记录,以及使用同步日志记录进行审计跟踪。) - 在某些罕见情况下,必须注意可变消息。大多数情况下,您无需担心这一点。Log4 将确保像
logger.debug("My object is {}", myObject)这样的日志消息将在调用logger.debug()时使用myObject参数的状态。即使myObject稍后被修改,日志消息也不会改变。异步记录可变对象是安全的,因为 Log4j 中内置的大多数 Message 实现都会对参数进行快照。但是,有一些例外:MapMessage 和 StructuredDataMessage 都是可变的:在创建消息对象后,可以向这些消息添加字段。这些消息不应在使用异步日志记录器或异步追加器记录后进行修改;您可能在生成的日志输出中看到这些修改,也可能看不到。类似地,自定义 Message 实现应在设计时考虑异步使用,并在构造时对参数进行快照,或者记录其线程安全特性。 - 如果您的应用程序在 CPU 资源稀缺的环境中运行,例如一台只有一个 CPU 和一个内核的机器,启动另一个线程不太可能带来更好的性能。
- 如果您的应用程序记录消息的持续速率快于底层追加器的最大持续吞吐量,队列将填满,应用程序最终将以最慢的追加器的速度进行日志记录。如果发生这种情况,请考虑选择一个 更快的追加器,或者减少日志记录。如果这两个选项都不行,您可以通过同步日志记录获得更好的吞吐量和更少的延迟峰值。
使所有日志记录器异步
Log4j-2.9 及更高版本需要在类路径上使用 disruptor-3.3.4.jar 或更高版本。在 Log4j-2.9 之前,需要 disruptor-3.0.0.jar 或更高版本。
这是最简单的配置方法,并且可以提供最佳性能。要使所有日志记录器异步,请将 disruptor jar 添加到类路径,并将系统属性 log4j2.contextSelector 设置为 org.apache.logging.log4j.core.async.AsyncLoggerContextSelector 或 org.apache.logging.log4j.core.async.BasicAsyncLoggerContextSelector。
默认情况下,异步日志记录器不会将 位置 传递给 I/O 线程。如果您的布局或自定义过滤器需要位置信息,您需要在所有相关日志记录器的配置中设置“includeLocation=true”,包括根日志记录器。
不需要位置的配置可能如下所示
<?xml version="1.0" encoding="UTF-8"?>
<!-- Don't forget to set system property
-Dlog4j2.contextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector
or
-Dlog4j2.contextSelector=org.apache.logging.log4j.core.async.BasicAsyncLoggerContextSelector
to make all loggers asynchronous. -->
<Configuration status="WARN">
<Appenders>
<!-- Async Loggers will auto-flush in batches, so switch off immediateFlush. -->
<RandomAccessFile name="RandomAccessFile" fileName="async.log" immediateFlush="false" append="false">
<PatternLayout>
<Pattern>%d %p %c{1.} [%t] %m %ex%n</Pattern>
</PatternLayout>
</RandomAccessFile>
</Appenders>
<Loggers>
<Root level="info" includeLocation="false">
<AppenderRef ref="RandomAccessFile"/>
</Root>
</Loggers>
</Configuration>当使用 AsyncLoggerContextSelector 或 BasicAsyncLoggerContextSelector 使所有日志记录器异步时,请确保在配置中使用正常的 <root> 和 <logger> 元素。上下文选择器将确保所有日志记录器都是异步的,使用与配置 <asyncRoot> 或 <asyncLogger> 时不同的机制。后者的元素旨在将异步与同步日志记录器混合使用。如果您将两种机制一起使用,您将最终获得两个后台线程,其中您的应用程序将日志消息传递给线程 A,线程 A 将消息传递给线程 B,然后线程 B 最终将消息记录到磁盘。这可以工作,但中间会有一步是不必要的。
您可以使用一些系统属性来控制异步日志子系统的各个方面。其中一些属性可用于调整日志性能。
还可以通过创建名为log4j2.component.properties的文件并将此文件包含在应用程序的类路径中来指定以下属性。
请注意,在 Log4j 2.10.0 中,系统属性已重命名为更一致的样式。所有旧的属性名称仍然受支持,这些名称在此处有记录。
| 系统属性 | 默认值 | 描述 |
|---|---|---|
| log4j2.asyncLoggerExceptionHandler |
默认处理程序
|
实现com.lmax.disruptor.ExceptionHandler接口的类的完全限定名称。该类需要具有一个公共的无参数构造函数。如果指定,则在记录消息时发生异常时,将通知此类。如果未指定,则默认异常处理程序将向标准错误输出流打印一条消息和堆栈跟踪。 |
| log4j2.asyncLoggerRingBufferSize | 256 * 1024 | 异步日志子系统使用的 RingBuffer 中的大小(插槽数量)。使此值足够大以处理突发活动。最小大小为 128。RingBuffer 将在首次使用时预先分配,并且在系统生命周期内永远不会增长或缩小。 当应用程序的日志记录速度快于底层追加器能够跟上的速度,并且持续时间足够长以填满队列时,行为将由AsyncQueueFullPolicy决定。 |
| log4j2.asyncLoggerWaitStrategy |
超时
|
有效值:Block、Timeout、Sleep、Yield。(另请参见下面的自定义 WaitStrategy部分。)Block是一种策略,它使用锁和条件变量来使 I/O 线程等待日志事件。当吞吐量和低延迟不像 CPU 资源那样重要时,可以使用 Block。建议用于资源受限/虚拟化环境。Timeout是Block策略的一种变体,它将定期从锁条件 await() 调用中唤醒。这确保了如果以某种方式错过了通知,则消费者线程不会卡住,而是会以很小的延迟(默认值为 10 毫秒)恢复。Sleep是一种策略,它最初会旋转,然后使用 Thread.yield(),最终会将 I/O 线程等待日志事件时允许的最小纳秒数停放。Sleep 是性能和 CPU 资源之间的一个很好的折衷方案。这种策略对应用程序线程的影响非常小,以换取一些额外的延迟来实际记录消息。Yield是一种策略,它在最初旋转后使用 Thread.yield() 来等待日志事件。Yield 是性能和 CPU 资源之间的一个很好的折衷方案,但为了更快地将消息记录到磁盘,它可能比 Sleep 使用更多的 CPU。 |
| log4j2.asyncLoggerTimeout |
10
|
TimeoutBlockingWaitStrategy的超时时间(以毫秒为单位)。有关详细信息,请参见 WaitStrategy 系统属性。 |
| log4j2.asyncLoggerSleepTimeNs |
100
|
SleepingWaitStrategy的睡眠时间(以纳秒为单位)。有关详细信息,请参见 WaitStrategy 系统属性。 |
| log4j2.asyncLoggerRetries |
200
|
SleepingWaitStrategy的总旋转周期数和Thread.yield()周期数。有关详细信息,请参见 WaitStrategy 系统属性。 |
| AsyncLogger.SynchronizeEnqueueWhenQueueFull |
true
|
当队列已满时,同步对 Disruptor 环形缓冲区的访问以阻塞入队操作。当应用程序的日志记录速度快于底层追加器能够跟上的速度,并且环形缓冲区已满时,用户遇到 Disruptor v3.4.2 的过度 CPU 利用率,尤其是在应用程序线程数量远远超过核心数量时。通过限制对入队操作的访问,可以显着降低 CPU 利用率。将此值设置为false可能会导致异步日志队列已满时 CPU 利用率非常高。 |
| log4j2.asyncLoggerThreadNameStrategy |
CACHED
|
有效值:CACHED、UNCACHED。 默认情况下,AsyncLogger 会在 ThreadLocal 变量中缓存线程名称以提高性能。如果您的应用程序在运行时修改了线程名称(使用 Thread.currentThread().setName()),并且您希望看到日志中反映出新的线程名称,请指定UNCACHED选项。 |
| log4j2.clock |
SystemClock
|
您还可以指定实现 |
还有一些系统属性可用于即使在底层追加器无法跟上日志记录速率并且队列正在填满的情况下也能保持应用程序吞吐量。有关系统属性log4j2.asyncQueueFullPolicy和log4j2.discardThreshold的详细信息,请参见。
混合同步和异步记录器
Log4j-2.9 及更高版本需要类路径中的 disruptor-3.3.4.jar 或更高版本。在 Log4j-2.9 之前,需要 disruptor-3.0.0.jar 或更高版本。无需将系统属性“Log4jContextSelector”设置为任何值。
可以在配置中组合同步和异步记录器。这为您提供了更大的灵活性,但会以略微降低性能为代价(与使所有记录器都异步相比)。使用<asyncRoot>或<asyncLogger>配置元素来指定需要异步的记录器。一个配置只能包含一个根记录器(<root>或<asyncRoot>元素),但除此之外,可以组合异步和非异步记录器。例如,包含<asyncLogger>元素的配置文件也可以包含用于同步记录器的<root>和<logger>元素。
默认情况下,异步日志记录器不会将 位置 传递给 I/O 线程。如果您的布局或自定义过滤器需要位置信息,您需要在所有相关日志记录器的配置中设置“includeLocation=true”,包括根日志记录器。
混合异步记录器的配置可能如下所示
<?xml version="1.0" encoding="UTF-8"?>
<!-- No need to set system property "log4j2.contextSelector" to any value
when using <asyncLogger> or <asyncRoot>. -->
<Configuration status="WARN">
<Appenders>
<!-- Async Loggers will auto-flush in batches, so switch off immediateFlush. -->
<RandomAccessFile name="RandomAccessFile" fileName="asyncWithLocation.log"
immediateFlush="false" append="false">
<PatternLayout>
<Pattern>%d %p %class{1.} [%t] %location %m %ex%n</Pattern>
</PatternLayout>
</RandomAccessFile>
</Appenders>
<Loggers>
<!-- pattern layout actually uses location, so we need to include it -->
<AsyncLogger name="com.foo.Bar" level="trace" includeLocation="true">
<AppenderRef ref="RandomAccessFile"/>
</AsyncLogger>
<Root level="info" includeLocation="true">
<AppenderRef ref="RandomAccessFile"/>
</Root>
</Loggers>
</Configuration>您可以使用一些系统属性来控制异步日志子系统的各个方面。其中一些属性可用于调整日志性能。
还可以通过创建名为log4j2.component.properties的文件并将此文件包含在应用程序的类路径中来指定以下属性。
请注意,在 Log4j 2.10 中,系统属性已重命名为更一致的样式。所有旧的属性名称仍然受支持,这些名称在此处有记录。
| 系统属性 | 默认值 | 描述 |
|---|---|---|
| log4j2.asyncLoggerConfigExceptionHandler |
默认处理程序
|
实现com.lmax.disruptor.ExceptionHandler接口的类的完全限定名称。该类需要具有一个公共的无参数构造函数。如果指定,则在记录消息时发生异常时,将通知此类。如果未指定,则默认异常处理程序将向标准错误输出流打印一条消息和堆栈跟踪。 |
| log4j2.asyncLoggerConfigRingBufferSize | 256 * 1024 | 异步日志子系统使用的 RingBuffer 中的大小(插槽数量)。使此值足够大以处理突发活动。最小大小为 128。RingBuffer 将在首次使用时预先分配,并且在系统生命周期内永远不会增长或缩小。 当应用程序的日志记录速度快于底层追加器能够跟上的速度,并且持续时间足够长以填满队列时,行为将由AsyncQueueFullPolicy决定。 |
| log4j2.asyncLoggerConfigWaitStrategy |
超时
|
有效值:Block、Timeout、Sleep、Yield。(另请参见下面的自定义 WaitStrategy部分。)Block是一种策略,它使用锁和条件变量来使 I/O 线程等待日志事件。当吞吐量和低延迟不像 CPU 资源那样重要时,可以使用 Block。建议用于资源受限/虚拟化环境。Timeout是Block策略的一种变体,它将定期从锁条件 await() 调用中唤醒。这确保了如果以某种方式错过了通知,则消费者线程不会卡住,而是会以很小的延迟(默认值为 10 毫秒)恢复。Sleep是一种策略,它最初会旋转,然后使用 Thread.yield(),最终会将 I/O 线程等待日志事件时允许的最小纳秒数停放。Sleep 是性能和 CPU 资源之间的一个很好的折衷方案。这种策略对应用程序线程的影响非常小,以换取一些额外的延迟来实际记录消息。Yield是一种策略,它在最初旋转后使用 Thread.yield() 来等待日志事件。Yield 是性能和 CPU 资源之间的一个很好的折衷方案,但为了更快地将消息记录到磁盘,它可能比 Sleep 使用更多的 CPU。 |
| log4j2.asyncLoggerConfigTimeout |
10
|
TimeoutBlockingWaitStrategy的超时时间(以毫秒为单位)。有关详细信息,请参见 WaitStrategy 系统属性。 |
| log4j2.asyncLoggerConfigSleepTimeNs |
100
|
SleepingWaitStrategy的睡眠时间(以纳秒为单位)。有关详细信息,请参见 WaitStrategy 系统属性。 |
| log4j2.asyncLoggerConfigRetries |
200
|
SleepingWaitStrategy的总旋转周期数和Thread.yield()周期数。有关详细信息,请参见 WaitStrategy 系统属性。 |
| AsyncLoggerConfig.SynchronizeEnqueueWhenQueueFull |
true
|
当队列已满时,同步对 Disruptor 环形缓冲区的访问以阻塞入队操作。当应用程序的日志记录速度快于底层追加器能够跟上的速度,并且环形缓冲区已满时,用户遇到 Disruptor v3.4.2 的过度 CPU 利用率,尤其是在应用程序线程数量远远超过核心数量时。通过限制对入队操作的访问,可以显着降低 CPU 利用率。将此值设置为false可能会导致异步日志队列已满时 CPU 利用率非常高。 |
还有一些系统属性可用于即使在底层追加器无法跟上日志记录速率并且队列正在填满的情况下也能保持应用程序吞吐量。有关系统属性log4j2.asyncQueueFullPolicy和log4j2.discardThreshold的详细信息,请参见。
自定义 WaitStrategy
上面提到的系统属性只允许从一组预定义的 WaitStrategy 中进行选择。在某些情况下,您可能希望配置此列表中不存在的自定义 WaitStrategy。这可以通过在 Log4j 配置中使用AsyncWaitStrategyFactory元素来实现。
配置自定义 WaitStrategy 的配置可能如下所示
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<AsyncWaitStrategyFactory
class="my.custom.AsyncWaitStrategyFactory" />
<Appenders>
<File name="MyFile" fileName="logs/app.log">
<PatternLayout pattern="%d %p %c{1.} [%t] %m%n" />
</File>
</Appenders>
<Loggers>
<AsyncRoot level="info">
<AppenderRef ref="MyFile"/>
</AsyncRoot>
</Loggers>
</Configuration>指定的类必须实现org.apache.logging.log4j.core.async.AsyncWaitStrategyFactory接口,该接口定义如下
public interface AsyncWaitStrategyFactory {
/**
* Returns a non-null implementation of the LMAX Disruptor's WaitStrategy interface.
* This WaitStrategy will be used by Log4j Async Loggers and Async LoggerConfigs.
*
* @return the WaitStrategy instance to be used by Async Loggers and Async LoggerConfigs
*/
WaitStrategy createWaitStrategy();
}
指定的类还必须具有一个公共的无参数构造函数;Log4j 将实例化指定工厂类的实例,并使用此工厂来创建所有异步记录器使用的 WaitStrategy。
如果配置了AsyncWaitStrategyFactory,则会忽略与 WaitStrategy 相关的系统属性。
位置、位置、位置...
如果其中一个布局配置了与位置相关的属性,例如 HTML locationInfo,或其中一个模式%C 或 $class、%F 或 %file、%l 或 %location、%L 或 %line、%M 或 %method,Log4j 将对堆栈进行快照,并遍历堆栈跟踪以查找位置信息。
这是一个昂贵的操作:对于同步记录器,速度慢 1.3-5 倍。同步记录器会在尽可能长时间地等待后才进行此堆栈快照。如果不需要位置,则永远不会进行快照。
但是,异步记录器需要在将日志消息传递给另一个线程之前做出此决定;位置信息将在该点之后丢失。对于异步记录器,进行堆栈跟踪快照的性能影响甚至更高:使用位置进行日志记录比不使用位置慢 30-100 倍。因此,异步记录器和异步追加器默认情况下不包含位置信息。
您可以在记录器或异步追加器配置中通过指定includeLocation="true"来覆盖默认行为。
异步日志记录性能
以下吞吐量性能结果来自运行 PerfTest、MTPerfTest 和 PerfTestDriver 类,这些类可以在 Log4j 2 单元测试源目录中找到。对于吞吐量测试,使用的方法是
- 首先,通过记录 200,000 条 500 个字符的日志消息来预热 JVM。
- 重复预热 10 次,然后等待 10 秒钟,让 I/O 线程赶上来并清空缓冲区。
- 测量执行 256 * 1024 / threadCount 次 Logger.log 调用需要多长时间,并将结果表示为每秒消息数。
- 重复测试 5 次,并对结果进行平均。
以下结果是在 log4j-2.0-beta5、disruptor-3.0.0.beta3、log4j-1.2.17 和 logback-1.0.10 上获得的。
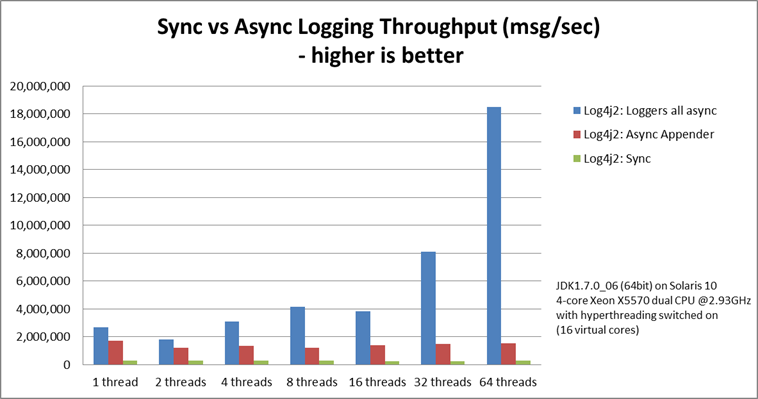
日志记录峰值吞吐量
下图比较了同步记录器、异步追加器和异步记录器的吞吐量。这是所有线程的总吞吐量。在使用 64 个线程的测试中,异步记录器比异步追加器快 12 倍,比同步记录器快 68 倍。
异步记录器的吞吐量随着线程数量的增加而增加,而同步记录器和异步追加器的吞吐量在进行日志记录的线程数量无论多少,都或多或少保持不变。
与其他日志记录包的异步吞吐量比较
我们还将异步记录器的峰值吞吐量与其他日志记录包中提供的同步记录器和异步追加器进行了比较,特别是 log4j-1.2.17 和 logback-1.0.10,结果相似。对于异步追加器,所有线程的总日志记录吞吐量在添加更多线程时大致保持不变。异步记录器在多线程场景中更有效地利用了机器上可用的多个核心。
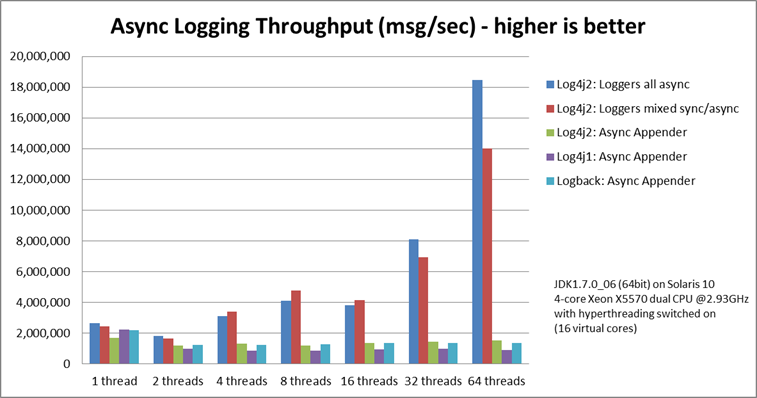
在 Solaris 10(64 位)上,使用 JDK1.7.0_06,4 核 Xeon X5570 双 CPU @2.93Ghz,超线程开启(16 个虚拟核心)
| 日志记录器 | 1 个线程 | 2 个线程 | 4 个线程 | 8 个线程 | 16 个线程 | 32 个线程 | 64 个线程 |
|---|---|---|---|---|---|---|---|
| Log4j 2:所有日志记录器异步 | 2,652,412 | 909,119 | 776,993 | 516,365 | 239,246 | 253,791 | 288,997 |
| Log4j 2:日志记录器混合同步/异步 | 2,454,358 | 839,394 | 854,578 | 597,913 | 261,003 | 216,863 | 218,937 |
| Log4j 2:异步追加器 | 1,713,429 | 603,019 | 331,506 | 149,408 | 86,107 | 45,529 | 23,980 |
| Log4j1:异步追加器 | 2,239,664 | 494,470 | 221,402 | 109,314 | 60,580 | 31,706 | 14,072 |
| Logback:异步追加器 | 2,206,907 | 624,082 | 307,500 | 160,096 | 85,701 | 43,422 | 21,303 |
| Log4j 2:同步 | 273,536 | 136,523 | 67,609 | 34,404 | 15,373 | 7,903 | 4,253 |
| Log4j1:同步 | 326,894 | 105,591 | 57,036 | 30,511 | 13,900 | 7,094 | 3,509 |
| Logback:同步 | 178,063 | 65,000 | 34,372 | 16,903 | 8,334 | 3,985 | 1,967 |
在 Windows 7(64 位)上,使用 JDK1.7.0_11,2 核 Intel i5-3317u CPU @1.70Ghz,超线程开启(4 个虚拟核心)
| 日志记录器 | 1 个线程 | 2 个线程 | 4 个线程 | 8 个线程 | 16 个线程 | 32 个线程 |
|---|---|---|---|---|---|---|
| Log4j 2:所有日志记录器异步 | 1,715,344 | 928,951 | 1,045,265 | 1,509,109 | 1,708,989 | 773,565 |
| Log4j 2:日志记录器混合同步/异步 | 571,099 | 1,204,774 | 1,632,204 | 1,368,041 | 462,093 | 908,529 |
| Log4j 2:异步追加器 | 1,236,548 | 1,006,287 | 511,571 | 302,230 | 160,094 | 60,152 |
| Log4j1:异步追加器 | 1,373,195 | 911,657 | 636,899 | 406,405 | 202,777 | 162,964 |
| Logback:异步追加器 | 1,979,515 | 783,722 | 582,935 | 289,905 | 172,463 | 133,435 |
| Log4j 2:同步 | 281,250 | 225,731 | 129,015 | 66,590 | 34,401 | 17,347 |
| Log4j1:同步 | 147,824 | 72,383 | 32,865 | 18,025 | 8,937 | 4,440 |
| Logback:同步 | 149,811 | 66,301 | 32,341 | 16,962 | 8,431 | 3,610 |
响应时间延迟
| 本节已使用 Log4j 2.6 版本重新编写。以前版本只报告了服务时间,而不是响应时间。请参阅性能页面上的响应时间侧边栏,了解为什么这过于乐观。此外,以前版本报告了平均延迟,这没有意义,因为延迟不是正态分布。最后,本节的以前版本只报告了高达 99.99% 的测量值的最高延迟,这并不能告诉你最糟糕的 0.01% 是什么。这很不幸,因为在响应时间方面,通常只有“异常值”才重要。从本版本开始,我们将尝试做得更好,并报告整个百分比范围内的响应时间延迟,包括所有异常值。感谢 Gil Tene 的如何不测量延迟演示。(现在我们知道为什么这也被称为“哦,糟糕!”演示。) |
响应时间是在特定负载下记录一条消息所需的时间。通常报告为延迟的实际上是服务时间:执行操作所需的时间。这掩盖了这样一个事实,即服务时间的一次峰值会为许多后续操作增加排队延迟。服务时间很容易测量(并且在纸面上通常看起来很好),但对于用户来说无关紧要,因为它省略了等待服务的时间。因此,我们报告响应时间:服务时间加上等待时间。
以下响应时间测试结果均来自运行 ResponseTimeTest 类,该类可以在 Log4j 2 单元测试源目录中找到。如果你想自己运行这些测试,以下是我们使用的命令行选项
- -Xms1G -Xmx1G(防止测试期间堆大小调整)
- -DLog4jContextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector -DAsyncLogger.WaitStrategy=busyspin(使用异步日志记录器。BusySpin 等待策略减少了一些抖动。)
- 经典模式:-Dlog4j2.enable.threadlocals=false -Dlog4j2.enable.direct.encoders=false
无垃圾模式:-Dlog4j2.enable.threadlocals=true -Dlog4j2.enable.direct.encoders=true - -XX:CompileCommand=dontinline,org.apache.logging.log4j.core.async.perftest.NoOpIdleStrategy::idle
- -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCApplicationStoppedTime(查看 GC 和安全点暂停)
以下图表比较了 Logback 1.1.7、Log4j 1.2.17 中基于 ArrayBlockingQueue 的异步追加器与 Log4j 2.6 提供的各种异步日志记录选项的响应时间延迟。在每秒 128,000 条消息的工作负载下,使用 16 个线程(每个线程以每秒 8,000 条消息的速度记录),我们看到 Logback 1.1.7、Log4j 1.2.17 经历的延迟峰值比 Log4j 2 大几个数量级。
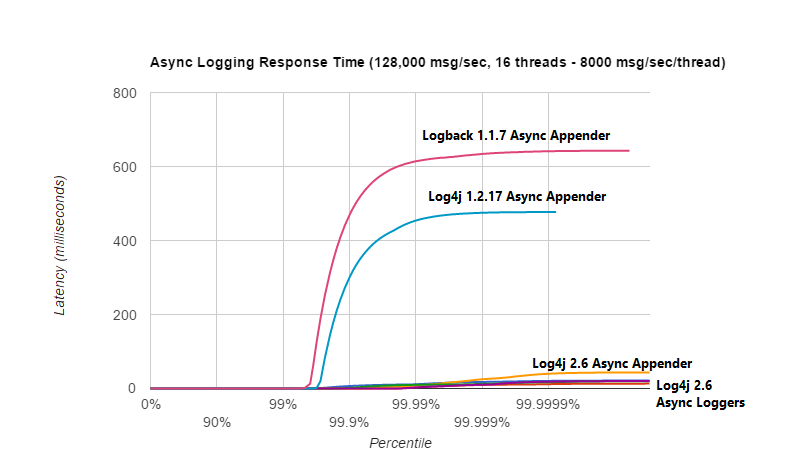
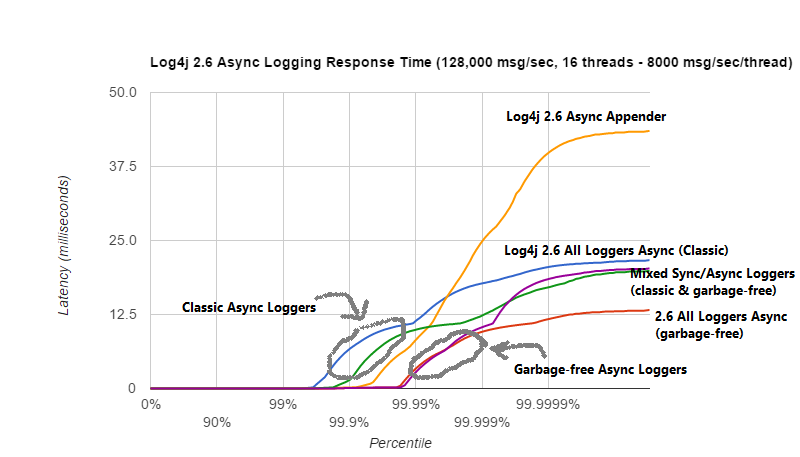
以下图表放大显示了同一测试的 Log4j 2 结果。我们看到,最坏情况下的响应时间对于基于 ArrayBlockingQueue 的异步追加器来说是最高的。无垃圾异步日志记录器具有最佳的响应时间行为。
幕后
异步日志记录器使用LMAX Disruptor 线程间消息传递库实现。来自 LMAX 网站
... 使用队列在系统各个阶段之间传递数据会导致延迟,因此我们专注于优化这一领域。Disruptor 是我们研究和测试的结果。我们发现,CPU 级别的缓存未命中以及需要内核仲裁的锁都非常昂贵,因此我们创建了一个框架,该框架对运行它的硬件具有“机械同情心”,并且是无锁的。
LMAX Disruptor 与java.util.concurrent.ArrayBlockingQueue 的内部性能比较可以在这里找到。